在线体验 DeepSeek OCR
OCR模型对比
看看 DeepSeek OCR 与传统解决方案的对比
| Model | Accuracy | Tokens/Page | Multilingual | Formulas | Charts | Open Source |
|---|---|---|---|---|---|---|
| DeepSeek-OCR ⭐ | 97% | 100 | ||||
| GOT-OCR 2.0 | 98% | 6000 | ||||
| MinerU 2.0 | 95% | 6000+ | ||||
| PaddleOCR | 90% | N/A | ||||
| ChatGPT 4o | ~85% | N/A |
行业领先的token恢复准确率
相比 GOT-OCR2.0 的256个token - 高效60%
A100-40G GPU的处理能力
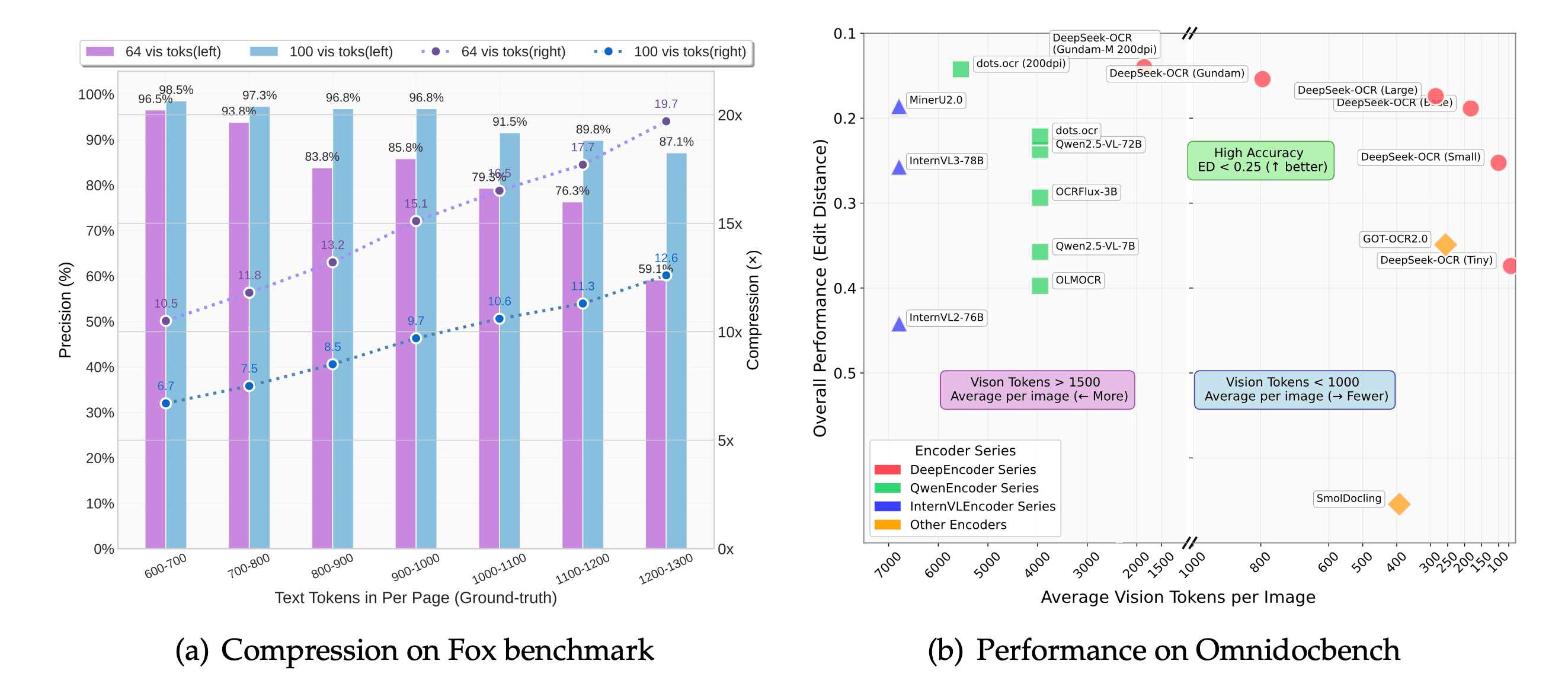
革命性的视觉即压缩技术
DeepSeek OCR通过将视觉理解视为压缩任务,实现了10倍无损压缩和20倍可用压缩。这一突破性技术在保持高准确率的同时,将token消耗降低了60倍。
- 视觉即压缩:64-100个视觉token替代600-1000+个文本token
- 定制视觉编码器(DeepEncoder)具有16倍原生压缩率
- 生产就绪:支持多语言文档、图表、表格和公式
如何使用 DeepSeek OCR
在线工具
上传图片/PDF,即时获得Markdown结果。每天10次免费转换 - 无需信用卡。
Python API
pip install deepseek-ocr,加载模型,调用infer() - 三行代码轻松集成。
vLLM批量处理
使用A100-40G GPU集群处理数千份文档,吞吐量约2500 tokens/s。
自托管部署
使用Docker、Kubernetes或任何云平台部署。完全控制您的数据和基础设施。
为什么选择 DeepSeek OCR?

超低Token消耗
每页100个token,而竞品需要256+。大规模文档处理可节省60%的API成本。
开源免费
30亿参数模型在GitHub上以Apache 2.0许可证开源。无供应商锁定,完全透明,社区驱动改进。

多分辨率支持
从Tiny(快速)、Small、Medium、Large到Gundam(超高质量)模式,根据您的准确率和速度需求选择。
全面的OCR功能
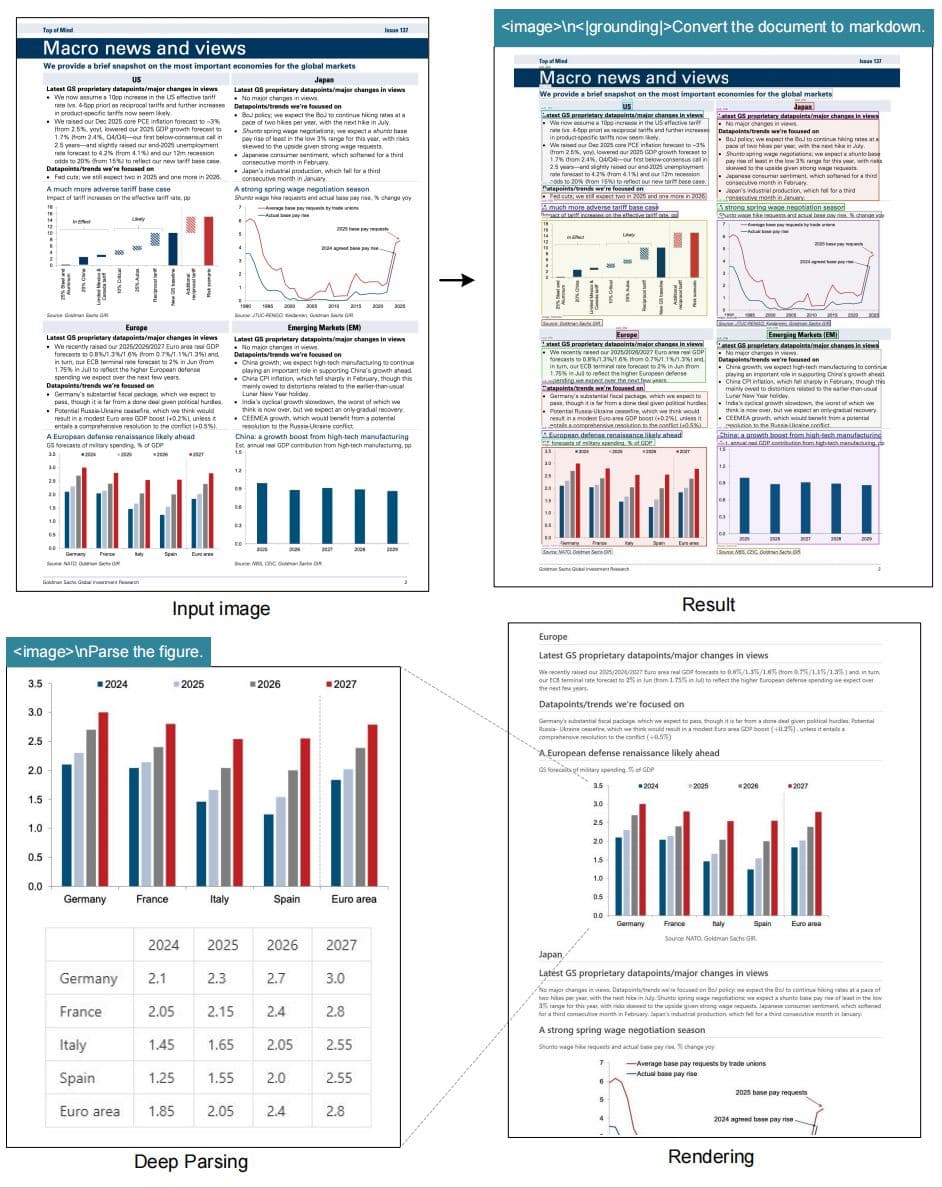
文档转Markdown
将任何文档转换为干净、结构化的Markdown,保留格式、标题、列表和链接。
多语言支持
支持100+种语言,包括英语、中文、日语、韩语、阿拉伯语以及混合语言文档。
图表解析
高精度提取图表、图形、示意图和技术图纸中的数据,保留结构。
公式识别
准确提取学术论文和教科书中的数学公式、方程式和LaTeX表达式。
多种分辨率模式
从Tiny(384px)到Gundam(1344px)的自适应质量设置,实现最佳速度-准确率权衡。
API与CLI支持
RESTful API、Python SDK和命令行工具,无缝集成到您的工作流程和应用程序中。
实际应用场景

学术研究论文
从PDF中提取公式、题注、参考文献和结构化内容。非常适合文献综述和引用管理。

技术文档
将技术手册、API文档和工程图纸转换为可搜索、可编辑的Markdown格式。

多语言商业文档
处理中英日混合文档、发票、合同和表单,跨语言高准确率。