Try Free OCR Demo - Instant Results
OCR Model Comparison
See how DeepSeek OCR stacks up against traditional solutions
| Model | Accuracy | Tokens/Page | Multilingual | Formulas | Charts | Open Source |
|---|---|---|---|---|---|---|
| DeepSeek-OCR ⭐ | 97% | 100 | ||||
| GOT-OCR 2.0 | 98% | 6000 | ||||
| MinerU 2.0 | 95% | 6000+ | ||||
| PaddleOCR | 90% | N/A | ||||
| ChatGPT 4o | ~85% | N/A |
Industry-leading token recovery accuracy
vs GOT-OCR2.0's 256 tokens - 60% more efficient
Processing capacity on A100-40G GPU
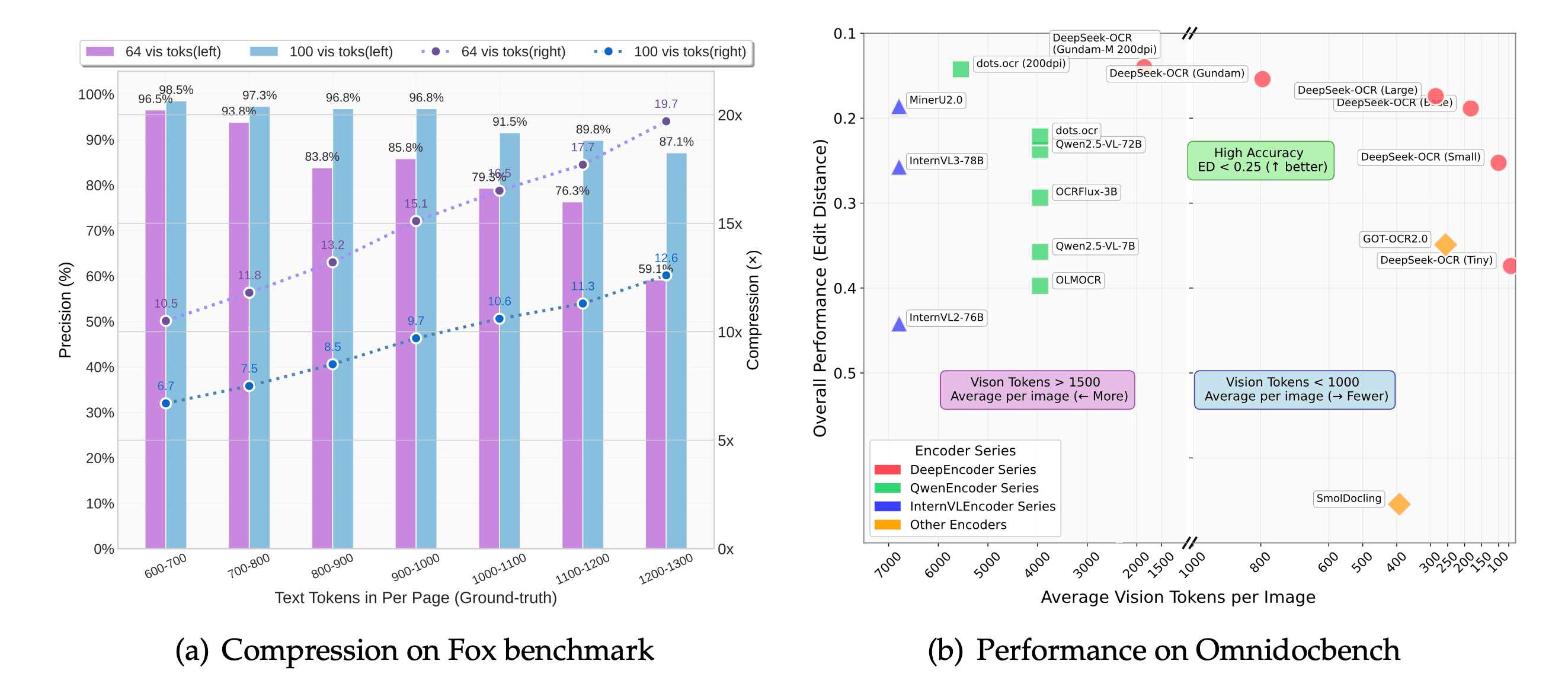
Vision-as-Compression: 60x More Efficient OCR
DeepSeek OCR achieves 10× lossless and 20× usable compression by treating vision understanding as a compression task. This breakthrough reduces token consumption by 60x compared to traditional OCR while maintaining high accuracy.
- Vision-as-Compression: 64-100 vision tokens replace 600-1000+ text tokens
- Custom Vision Encoder (DeepEncoder) with 16× native compression ratio
- Production-Ready: Supports multilingual documents, charts, tables, and formulas
4 Ways to Use DeepSeek OCR
Online Tool
Upload image/PDF, get instant Markdown results. 10 free conversions per day - no credit card required.
Python API
pip install deepseek-ocr, load model, call infer() - simple integration in 3 lines of code.
vLLM Batch Processing
Process thousands of documents with ~2500 tokens/s throughput on A100-40G GPU cluster.
Self-Hosted Deployment
Deploy with Docker, Kubernetes, or any cloud platform. Full control over your data and infrastructure.
Why DeepSeek OCR Outperforms Competitors

Ultra-Low Token Consumption
100 tokens per page vs 256+ for competitors. Save 60% on API costs for large-scale document processing.
Open Source & Free
3B parameter model available on GitHub with Apache 2.0 license. No vendor lock-in, full transparency, and community-driven improvements.

Multi-Resolution Support
Choose from Tiny (fast), Small, Medium, Large, to Gundam (ultra-high quality) modes based on your accuracy and speed requirements.
6 Powerful OCR Features You'll Love
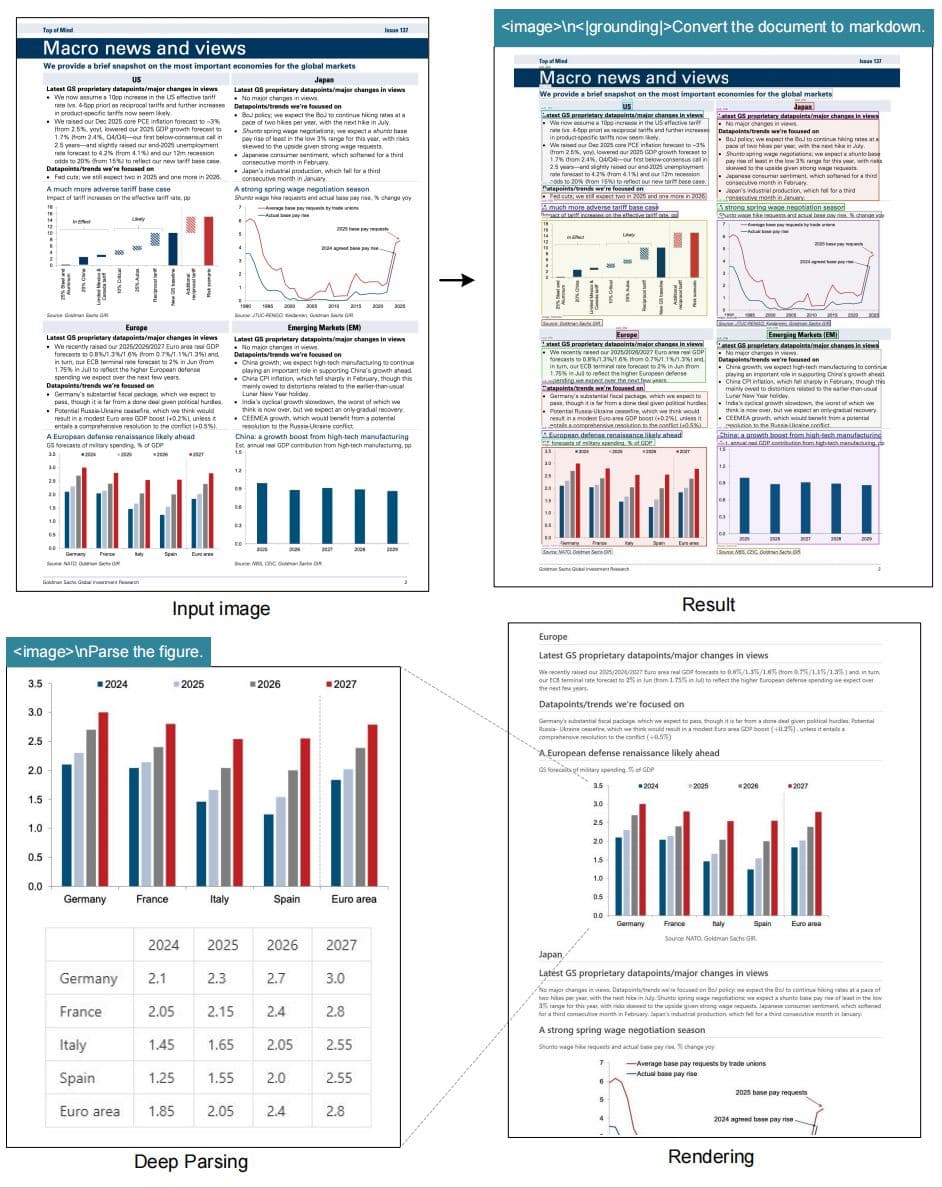
Document to Markdown
Convert any document into clean, structured Markdown with preserved formatting, headers, lists, and links.
Multi-Language Support
Supports 100+ languages including English, Chinese, Japanese, Korean, Arabic, and mixed-language documents.
Chart & Figure Parsing
Extract data from charts, graphs, diagrams, and technical drawings with high precision and structure preservation.
Formula Recognition
Accurately extract mathematical formulas, equations, and LaTeX expressions from academic papers and textbooks.
Multiple Resolution Modes
Adaptive quality settings from Tiny (384px) to Gundam (1344px) for optimal speed-accuracy trade-offs.
API & CLI Support
RESTful API, Python SDK, and command-line tools for seamless integration into your workflow and applications.
Popular Use Cases: Research, Docs & Business

Academic Research Papers
Extract formulas, captions, references, and structured content from PDFs. Perfect for literature reviews and citation management.

Technical Documentation
Convert technical manuals, API docs, and engineering diagrams to searchable, editable Markdown format.

Multilingual Business Documents
Process mixed English-Chinese-Japanese documents, invoices, contracts, and forms with high accuracy across languages.